Java Collection FrameWork
자료구조는 Data Structure 라고 불리고, 데이터 구조, 자세히 말하면 ‘일련의 일정 타입들의 데이터 모임 또는 관계를 나타낸 구성체’ 라고 할 수 있다.
알고리즘 문제를 풀어낼 때 우리가 효율적으로 문제를 풀어내기 위해서는 자료구조을 선택하는 것이 중요하다. 보통 알고리즘 문제를 해석하고 그 해석에 맞는 알고리즘을 선택하는게 보통이다.
이렇듯 알고리즘과 자료구조는 서로 의존적인 관계이기 때문에 알고리즘을 짜기 위해서는 꼭 자료구조를 잘 파악하고 있어야한다.
자료구조는 프로그래밍의 가장 기본이기 때문에 많은 언어들에서도 표준 라이브러리로 다양한 자료구조를 지원하고 있다.
그 중 자바의 대표적인 자료구조인 Collection을 배우고 직접 구현해보자.
자료구조의 분류
자료 구조의 대표적인 분류 방법은 선형 자료구조(Linear Data Structure)과 비선형 자료구조(Nonlinear Data Structure)로 나뉜다.
이러한 분류를 보통 대략적으로 ‘형태에 따른 자료구조’라고 보고, 각 자료구조에 알맞게 구체화 된 것들을 ‘구현된 자료구조’라고 한다.
선형 자료구조(Linear Data Structure)
쉽게 말해 데이터가 일렬로 연결된 형태이다. 흔히 쓰는 int[] 배열 같은 것이 대표적인 예이다. 선형 자료구조에는 리스트(List)와 큐(Queue), 덱(Deque)가 있다.
비선형 자료구조(Nonliner Data Structure)
선형 자료구조의 반대이다. 일렬로 나열된 것이 아닌, 각 요소가 여러 개의 요소와 연결 된 형태라고 생각하면 된다. 쉽게 생각해 거미줄 같다고 보면 된다. 대표적인 비선형 자료구조로는 그래프(Graph)와 트리(Tree)가 있다.
그리고 앞으로 설명 할 자료구조 중 위 두 가지 분류에 해당되지 않는 것이 있는 집합(Set)이 있다. 보통 기타 자료구조 또는 집합 자료구조로 본다. 집합의 경우는 데이터가 연결 된 형식이 아니다. 집합(Set)은 table에 가까운 자료구조라고 본다.
파일 자료구조도 있는데, 파일 구조는 순차파일, 색인파일, 직접파일이 있다는 것 정도만 알아두고 다음에 다루자.
Java Collection FrameWork
Java Collection FrameWork의 의미부터 파악해보자.
Java는 언어를 의미하고, Collection은 비슷한 류의 데이터를 쉽게 다루기 위해 모아놓은 것들을 가공 및 처리 할 수 있도록 지원하는 자료구조라는 의미이고, FrameWork는 어떤 문제를 해결하기 위한 구조의 뼈대가 되는 기본 구조를 의미한다.(공사를 할 때 기본 틀을 잡기 위해 철근 등을 박아 전체적인 틀을 만드는 것과 비슷하다.)
위 세가지 단어를 연결해 생각해본다면, 자바에서 비슷한 류의 데이터를 쉽게 다르기 위해 모은 자료구조들의 뼈대라고 볼 수 있다.
자바에서 기본 구조를 대표하는 것이 있다. 바로 Interface(인터페이스)이다. 인터페이스 자체가 기본 뼈대(추상 구조)만을 제공한다. 이렇듯 실제로 자바에서 제공하는 Collection은 크게 3가지 인터페이스(뼈대)로 나뉘어있다.
List(리스트), Queue(큐), Set(셋)으로 나뉘고, ‘형태에 따른 자료구조’라고 볼 수 있다. 아래 그림을 통해 살펴보자.
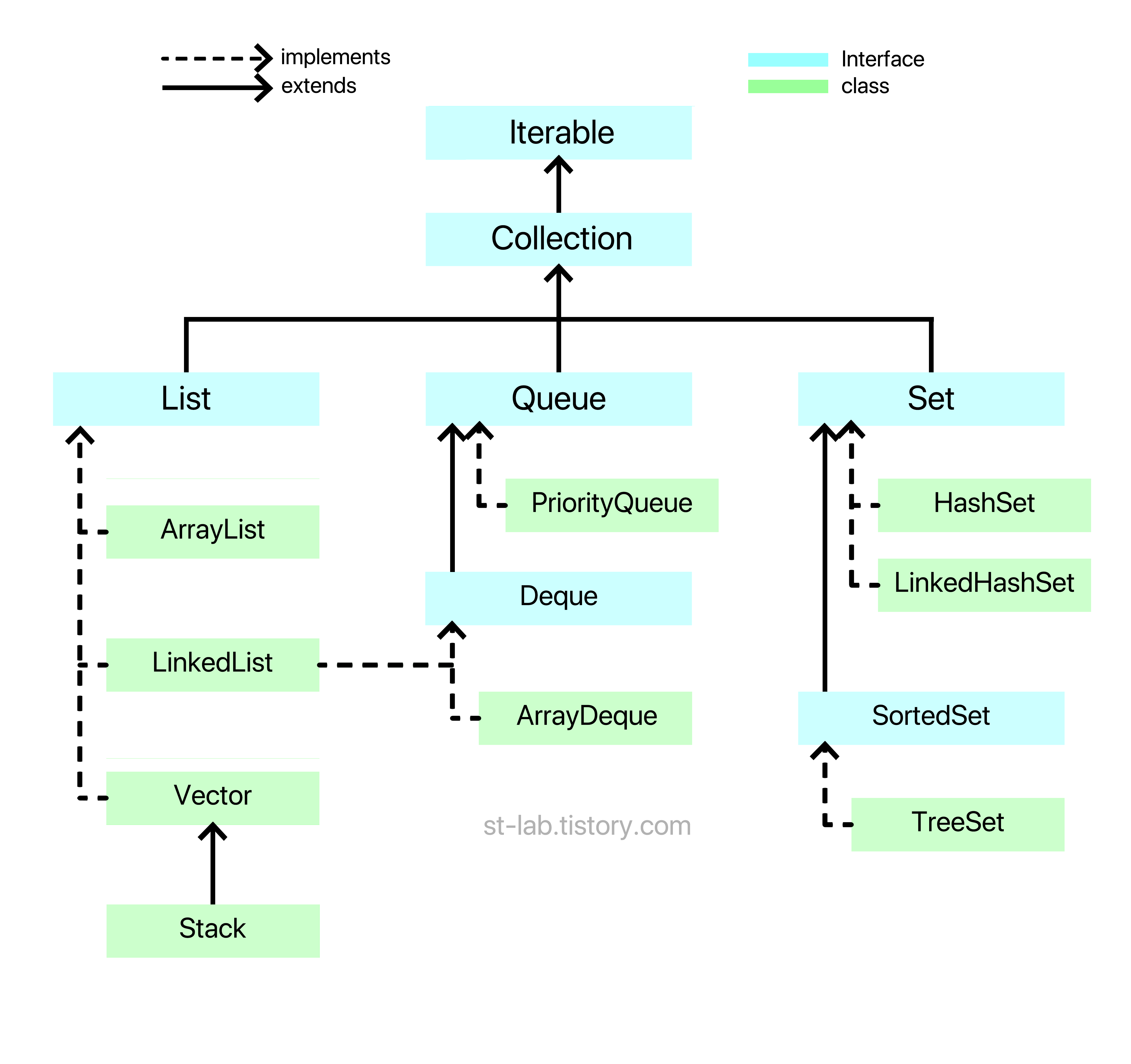
알다시피 점선은 구현 관계, 실선은 확장 관계다. 또한 Collection을 구현한 클래스 및 인터페이스들은 모두 java.util 패키지에 있다.
보다시피 Collection 인터페이스를 extends하는 List, Queue, Set 인터페이스가 있고, Queue와 Set 아래에는 그 인터페이스를 구체화 되어있는 Deque와 SortedSet이 있다. 자바에서 Interface를 class 파일에서 쓰면 보통 ‘구현한다’라고 한다. 위 그림과 같이 Collection Interface는 Collection 인터페이스를 상속하는 Interface들과 그 Interface를 구현한 class로 이루어져있다.
그럼 Collection 위에 있는 Iterable은 무엇일까?
Iterable이란, 컴퓨터 용어로 Iteration 이라는 단어가 ‘반복’, ‘되풀이’를 의미하는 것처럼, Iterable은 사전에 등재된 단어는 아니지만 ‘반복 가능한’이라는 뜻으로 알면 될 것 같다.
Collection 위에 Iterable이 있는 의미는 Collection 인터페이스에서 제공하는 class들은 모두 객체 형태로 내부 구현 또는 대개 Object[] 배열 형태가 아니라 각각의 객체를 갖고 움직인다. 그래서 객체의 데이터를 모두 순회하면서 출력하려면 사용자들이 각각의 데이터 순회 방법을 알거나 하나씩 get() 같이 메소드를 통해 데이터를 하나씩 꺼내와야 한다.
하지만 Iterable에서는 for-each를 제공한다. 즉, Iterable 인터페이스를 쓰는 모든 클래스들은 기복적으로 for-each 문법을 쉽게 사용할 수 있다. 한마디로 반복자로 구현되어 나오게 하는 것이다.
List (리스트)
List Interface는 대표적인 선형 자료구조로 주로 순서가 있는 데이터를 목록으로 이용할 수 있도록 만들어진 인터페이스다. 쉽게 이야기하면 int[] array = new int[10]; 처럼 쓴다. 하지만 이 처럼 선언한 배열의 경우 10개의 공간 외에는 더 이상 사용하지 못한다.
이러한 단점을 보완하여 List를 통해 구현된 class들은 ‘동적 크기’를 갖으며 배열처럼 사용할 수 있게 되어있다. 한마디로 배열의 기능 + 동적 크기 할당이 합쳐져 있다고 보면 된다.
<List Interface를 구현하는 클래스>
1. ArrayList
2. LinkedList
3. Vector (+ Vector를 상속받은 Stack)
<List Interface에 선언된 대표적인 메소드>
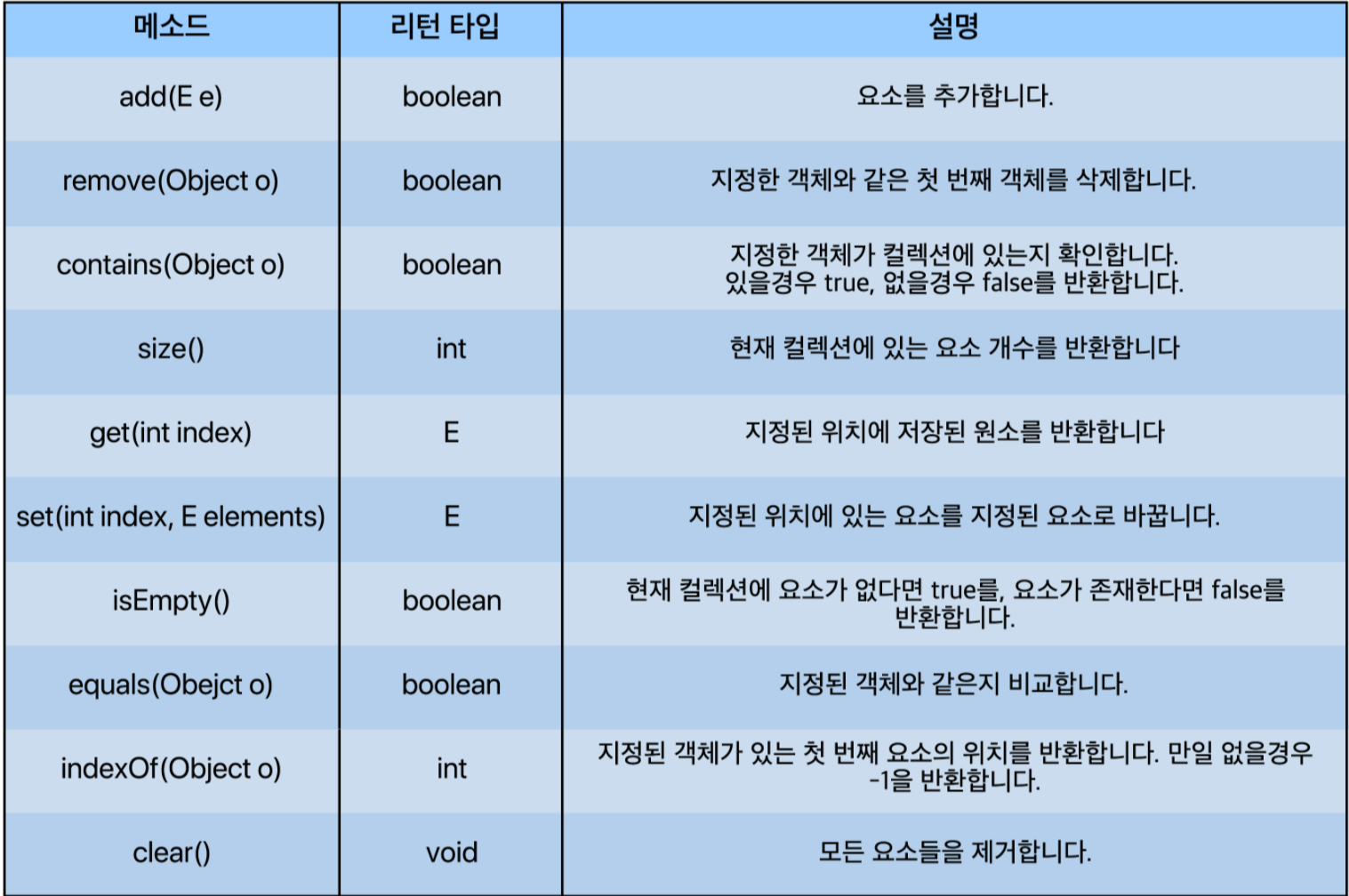
LIst를 구현하는 각 클래스들은 조금씩 특징이 다르다.
ArrayList
ArrayList는 Object[] 배열을 사용하면서 내부 구현을 통해 동적으로 관리를 한다. 우리가 흔히 쓰는 primitive 배열(ex int[])과 유사한 형태라고 보면 된다. 즉, 최상위 타입인 Object 타입으로 배열을 생성하여 사용하기 때문에 요소 접근(access elements)에서는 탁월한 성능을 보이나, 중간의 요소가 삽입, 삭제가 일어나는 경우 그 뒤의 요소들은 한 칸씩 밀어야 하거나 당겨야 하기 때문에 삽입, 삭제에서는 비효율적인 모습을 보인다.
LinkedList
LinkedList는 데이터(item)와 주소로 이루어진 클래스를 만들어 서로 연결하는 방식이다. 데이터와 주소로 이루어진 클래스를 Node(노드)라고 하는데, 각 노드는 이전의 노드와 다음 노드를 연결하는 방식인 것이다.(이중 연결 리스트라고도 한다.) 즉, 객체끼리 연결한 방식이다. 이렇다보니 요소를 검색해야 할 경우 처음 노드부터 찾으려는 노드가 나올 때 까지 연결된 노드들을 모두 방문해야한다는 점에서 성능이 떨어지나, 해당 노드를 삭제, 삽입해야 할 경우 해당 노드의 링크를 끊거나 연결만 해주면 되기 때문에 삽입, 삭제에서는 매우 좋은 효율을 보인다.
Vector
Vector는 자바를 배울 때 그리 자주 보이지는 않는 클래스인데, 기본적으로 ArrayList와 거의 같다고 보면 된다. Object[] 배열을 사용하며 요소 접근에서 빠른 성능을 보인다. 근데 왜 Vector가 있는 것이냐?라고 한다면, 원래 Vector는 Collection Framwork가 도입되기 전부터 지원하던 클래스였다. 그리고 Vector의 경우 항상 ‘동기화’를 지원한다. (쉽게 말하면 여러 쓰레드가 동시에 데이터에 접근하려하면 순차적으로 처리하도록 한다.) 그렇다보니 멀티 쓰레드에서는 안전하지만, 단일 쓰레드에서도 동기화를 하기 때문에 ArrayList에 비해 성능이 약간 느리다.
Stack
Stack은 우리가 흔히 생각하는 것처럼 쌓아 올리는 것이다. 전문용어로 말하면 LIFO(Last in First out) 또는 후입선출이라고 하는데, 쉽게 생각하면 우리가 짐을 쌓는다고 생각하면 쉽다. 짐을 쌓아올릴 때 가장 마지막에 쌓은 짐이 가장 위에 있을 것이다. 그리고 짐을 뺄 때도 가장 위에 있는 짐부터 빼게 될 것이다. 가장 대표적인 예시로는 웹페이지 ‘뒤로가기’가 있다. 우리가 새로운 페이지로 넘어갈 때마다 넘어가기 전 페이지를 스텍에 쌓고, 만약 뒤로가기를 누른다면 가장 위에 있는 페이지부터 꺼내오는 방식이다.
참고로 Stack의 경우 Vector클래스를 상속받고 있고, java에서 지원하는 Stack 클래스의 메소드들도 뜯어보면 알겠지만, 모두 Vector에 있는 메소드를 이용하여 구현되고 있어 크게 다를 것은 없다.
각 객체의 생성 방법은 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
/*
T는 객체 타입을 의미하며 기본적으로
Integer, String, Double, Long 같은 Wrapper Class부터
사용자 정의 객체까지 가능하다.
ex) LinkedList<Integer> list = new LinkedList<>();
primitive type은 불가능하다.
*/
// 방법 1
ArrayList<T> arraylist = new ArrayList<>();
LinkedList<T> linkedlist = new LinkedList<>();
Vector<T> vector = new Vector<>();
Stack<T> stack = new Stack<>();
// 방법 2
List<T> arraylist = new ArrayList<>();
List<T> linkedlist = new LinkedList<>();
List<T> vector = new Vector<>();
List<T> stack = new Stack<>();
// Stack은 Vector를 상속하기 때문에 아래와 같이 생성할 수 있다.
Vector<T> stack = new Stack<>();
new 라는 생성자 뒤에 객체를 명시해주기 때문에 상위 타입인 List
Queue(큐)
Queue Interface(큐 인터페이스)는 선형 자료구조로 주로 순서가 있는 데이터를 기반으로 ‘선입선출(先入先出, FIFO : First-in First-out)’을 위해 만들어진 인터페이스다.
흔히 Stack(스택)과 많이 비교를 하는 자료구조다. 큐에 대해 간단하게 말하자면 10, 20, 30, 40 순으로 데이터를 넣고, 데이터를 꺼낼 때(poll) 넣은 순서 그대로 10, 20, 30, 40이 나오는 구조라는 것이다. 이 때 가장 앞쪽에 있는 위치를 head(헤드)라고 부르고, 가장 후위(뒤)에 있는 위치를 tail(꼬리)라고 부른다. 예로들면, 놀이기구를 타기위해 줄서있는 모습을 상상하면 된다.
Collection 구조를 보면 알겠지만, Queue를 상속하고 있는 Deque(덱) 이라는 Interface도 있다. 둘 다 같은 부류인데 Queue는 한쪽 방향으로만(단방향) 삽입 삭제가 가능한 반면, Deque는 Double ended Queue라는 의미로 양쪽에서 삽입삭제가 가능한 자료구조라 보면 된다. 즉, head에서도 접근 가능하며, tail에서도 접근 가능한 양방향 큐라고 보면 된다.(Queue에서 확장된 형태)
쉽게 예로 들 수 있는 것은 카드 덱(deck)을 생각하면 된다. 카드를 중간에서 뺄 수는 없고, 맨 위에 놓거나, 맨 아래에 놓거나, 맨 위에 것을 빼거나, 맨 아래 것을 뺄 수 있는 것이라 생각하면 된다. (마침 발음도 같아 기억하기 쉬울 것이다.)
<Queue/Deque Interface를 구현하는 클래스>
1. LinkedList
2. ArrayDeque
3. PriorityQueue
<Queue/Deque Interface에 선언된 대표적인 메소드>
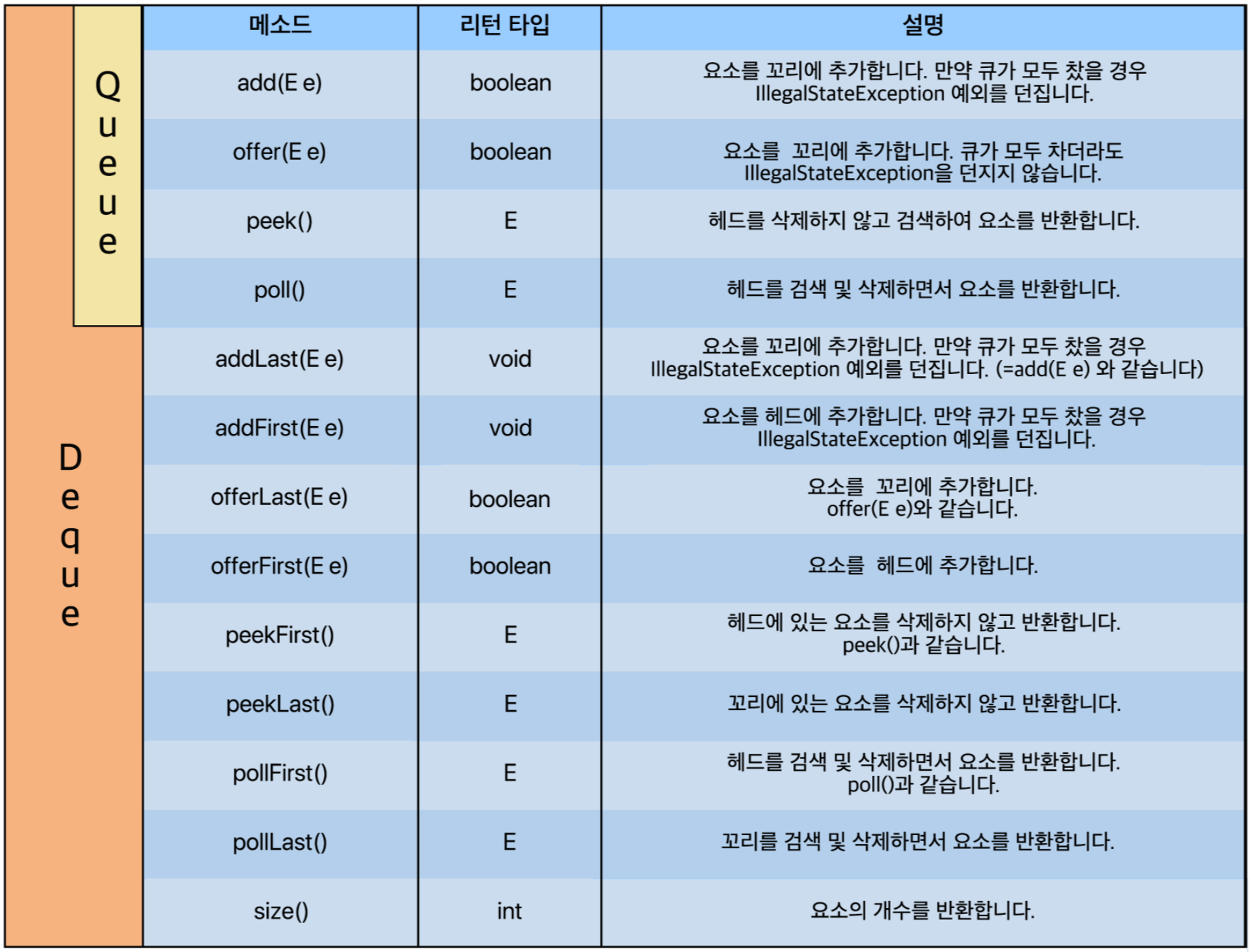
목록은 많아 보이지만 단순히 Deque는 양방향이기 때문에 헤드와 꼬리를 나누어 메소드가 더 생성 되었을 뿐이니 외울 것은 크게 없을 것이다.
그림을 보면 알겠지만 LinkedList는 List(리스트)를 구현하기도 하지만, Deque(덱)도 구현한다. 그리고 Deque Interface는 Queue Interface를 상속받는다.
즉, LinkedList는 사실상 3가지 용도로 쓸 수 있다는 것이다.
1. List
2. Deque
3. Queue
실제로도 LinkedList class를 보면 다음과 같이 List와 Deque를 모두 구현한다.
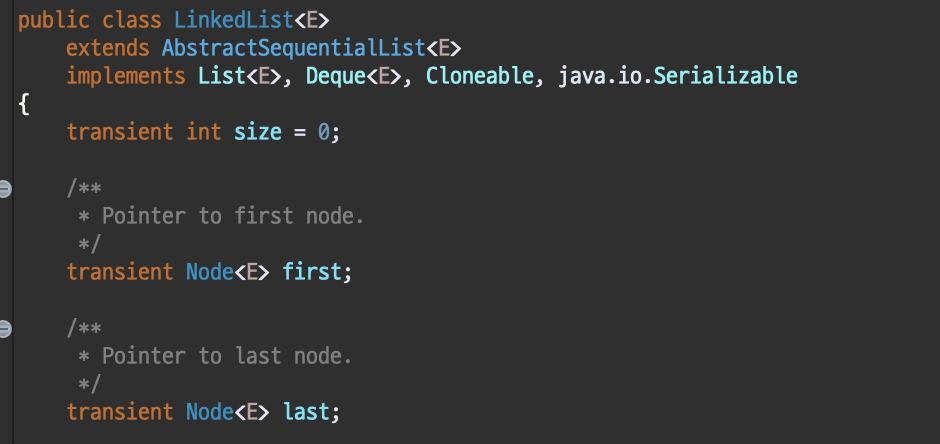
왜 LinkedList를 받을까? 앞서 List를 설명할 때도 말했지만, ArrayList와 LinkedList의 차이점은 Object[] 배열로 관리하느냐, Node라는 객체를 연결하여 관리하느냐의 차이였다.
마찬가지다. Deque 또는 Queue를 LinkedList 처럼 Node 객체로 연결해서 관리하길 원한다면 LinkedList를 쓰면 된다. 원리 자체는 크게 다르지 않기 때문에 LinkedList 하나에 다중 인터페이스를 포함하고 있는 것이다.
반대로 ArrayList처럼 Object[] 배열로 구현되어 있는 것은 ArrayDeque 이다. 물론 LinkedList와 ArrayDeque 둘 다 Deque을 구현하고 있고, Deque은 Queue를 상속받기 때문에 Queue로도 쓰일 수 있다.
만약 여러분들이 자바에서 지원하는 컬렉션에서 ‘일반적인 큐’를 사용하고자 한다면 LinkedList로 생성하여 Queue로 선언하면 된다. 쉽게 말해서 아래와 같이 선언하면 된다.
1
2
3
Queue<T> queue = new LinkedList<>();
//Deque()
Deque<T> queue = new LinkedList<>();
PriorityQueue는 뭘까?
단어 해석 그대로 ‘우선순위 큐’다. LinkedList는 Queue로 사용할 수 있다고 했다. 다만 큐의 원리가 선입선출이라는 전제 아래 짜여있다. 하지만 PriorityQueue는 ‘데이터 우선순위’에 기반하여 우선순위가 높은 데이터가 먼저 나오는 원리다. 따로 정렬방식을 지정하지 않는다면 낮은 숫자가 높은 우선순위를 갖는다. 쉽게 생각하면 정렬메소드인 sort()와 같은 순서로 데이터 우선순위를 갖는다는 의미다. PriorityQueue는 주어진 데이터들 중 최댓값, 혹은 최솟값을 꺼내올 때 매우 유용하게 사용될 수 있다. 다만, 사용자가 정의한 객체를 타입으로 쓸 경우 반드시 Comparator 또는 Comparable을 통해 정렬 방식을 구현해주어야 한다.
각 클래스별 생성 방법은 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
/*
T는 객체 타입을 의미하며 기본적으로
Integer, String, Double, Long 같은 Wrapper Class부터
사용자 정의 객체까지 가능하다.
단, primitive type은 불가능하다.
*/
ArrayDeque<T> arraydeque = new ArrayDeque<>();
PriorityQueue<T> priorityqueue = new PriorityQueue<>();
Deque<T> arraydeque = new ArrayDeque<>();
Deque<T> linkedlistdeque = new LinkedList<>();
Queue<T> arraydeque = new ArrayDeque<>();
Queue<T> linkedlistdeque = new LinkedList<>();
Queue<T> priorityqueue = new PriorityQueue<>();
Set(셋/세트)
Set(세트)는 말 그대로 ‘집합’이다. Set의 가장 큰 특징이라 하면 크게 두 가지가 있다. 첫 번째로 ‘데이터를 중복해서 저장할 수 없음’이다. 두 번째는 ‘입력 순서대로의 저장 순서를 보장하지 않는다’이다.
(다만 LinkedHashSet은 Set임에도 불구하고 입력 순서대로의 저장순서를 보장하고 있다. 그러나 데이터를 중복해서 저장할 수 없는 것은 같다.)
기본적으로 List계열은 index(Node)로 관리하기 때문에 add()같은 메소드를 쓰면 순서대로 저장되었다. Queue 계열 또한 우선순위 큐(PriorityQueue)를 제외하고는 기본적으로 입력한 순서대로 객체가 연결되어있다. 하지만 Set의 경우는 일반적으로 입력받은 순서와 상관없이 데이터를 집합시키기 때문에 입력받은 순서를 보장할 수 없다.
물론 순서 보장이 안된다는 불편함을 개선시키기 위해 만들어져 있는 것이 LinkedHashSet이다. 만약 데이터 중복을 허용하고 싶지 않은데 입력 순서를 보장받고 싶다면 LinkedHashSet을 사용하면 된다.
그리고 Queue와 유사하게 Set을 상속받고 있는 SortedSet Interface도 있다. 이름에서 어림짐작할 수 있으니 일단은 하나씩 천천히 알아보도록 하자.
<Set/SortedSet Interface를 구현하는 클래스>
1. HashSet
2. LinkedHashSet
3. TreeSet
<Set/ Interface에 선언된 대표적인 메소드>
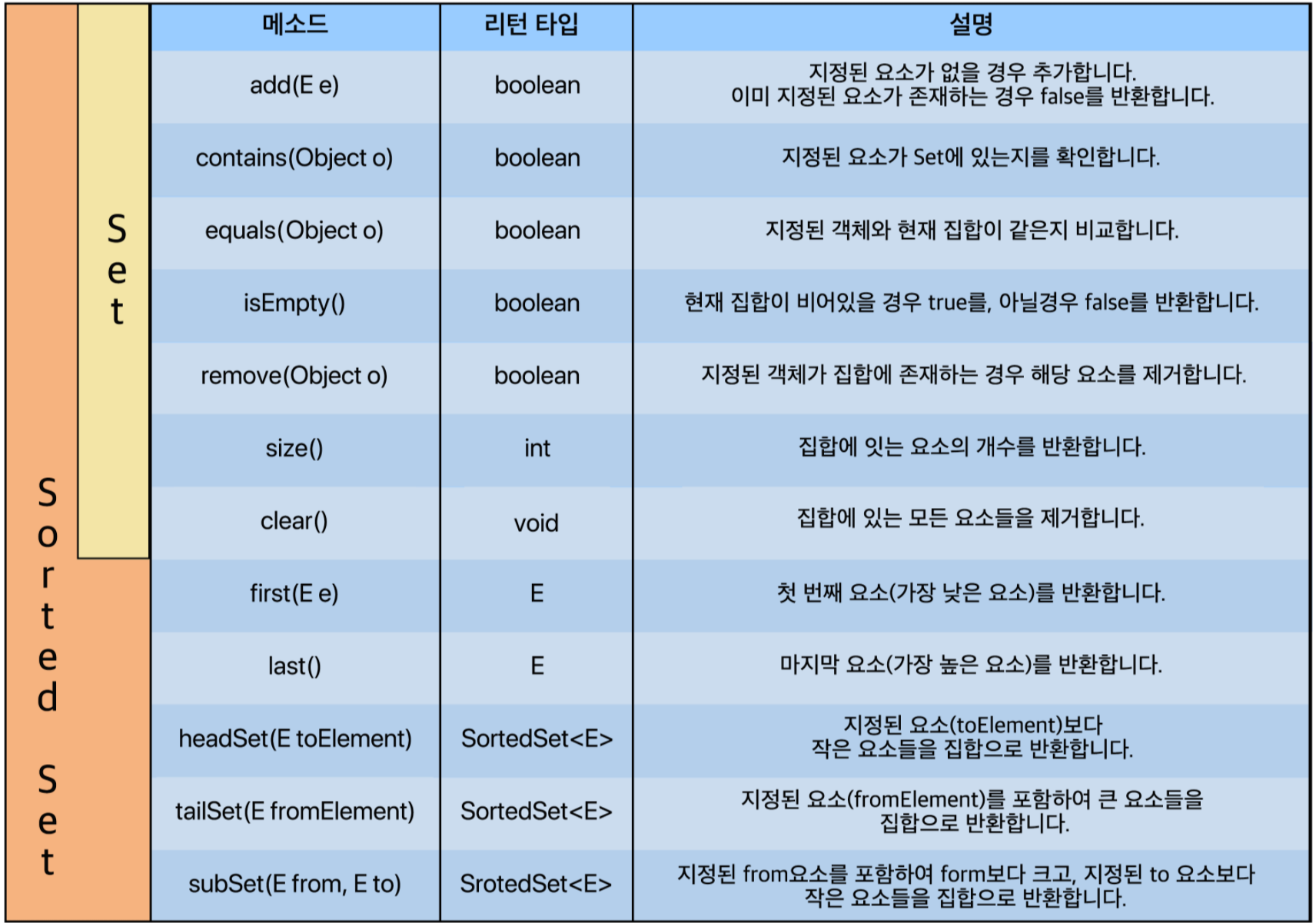
Set Interface을 구현하는 클래스들은 앞서 말했듯이 HashSet, LinkedHashSet, TreeSet 이렇게 3가지가 있다. 좀더 구체적으로 말하자면 TreeSet은 Set Interface를 상속받은 SortedSet Interface를 구현하고 있다. 그리고 Set의 가장 큰 특징은 ‘중복되는 데이터를 넣지 못한다는 점’이고, LinkedHashSet을 제외하고 대부분의 Set은 ‘입력 순서대로의 저장순서를 보장하지 않는다는 점’이다.
각 특징에 대해 간략하게 알아보자.
HashSet
먼저 HashSet이다. 가장 기본적인 Set 컬렉션의 클래스인데, 입력 순서를 보장하지 않고, 순서도 마찬가지로 보장되지 않는다. 그러면 어디에 쓰이냐는 생각이 들 수도 있다.
가장 쉽게 이해할 수 있는 예로는 여러분이 게임에서 ‘닉네임’을 만든다거나 아이디를 생성할 때 ‘중복확인’을 눌러 중복된 닉네임 또는 아이디인지 확인하는 것이다. 이는 데이터가 정렬되어있을 필요도 없고, 빠르게 중복되는 값인지만 찾으면 되기 때문에 유용한 방법이 될 수 있다.
좀 더 상세하게 말하자면 hash에 의해 데이터의 위치를 특정시켜 해당 데이터를 빠르게 색인(search)할 수 있게 만든 것이다. 즉, Hash 기능과 Set컬렉션이 합쳐진 것이 HashSet이다. 그렇기 때문에 삽입, 삭제, 색인이 매우 빠른 컬렉션 중 하나다.
LinkedHashSet
LinkedHashSet의 경우 이름에서 볼 수 있듯이 Link + Hash + Set 이 결합된 형태다. LinkedList에서 보면 add() 메소드를 통해 요소들을 넣은 순서대로 연결한다. 즉, LinkedList의 첫번째 요소부터 차례대로 출력하면 입력했던 순서대로 출력된다는 것이고 이는 순서를 보장한다는 의미다.
Set의 경우 기본적으로 입력 순서대로의 저장순서를 보장하지 않아 ‘중복은 허용하지 않으면서 순서를 보장받고 싶은경우’에는 불편할 수밖에 없다. 이를 보완하기 위해 존재하는 것이 바로 LinkedHashSet인 것이다. 실생활에서 그나마 예로 들자면 페이지를 열 때 만약 해당 페이지가 중복되경우 cache는 다시 적재할 필요는 없지만, 새로운 페이지를 할당해야 할 경우 최근에 사용되지 않은 cache을 비우고자 할 때, 가장 오래된 cache를 비우는 것이 현명할 것이다. 이를 LRU 알고리즘(Least Recently Used Algorithm)이라고 하는데, 이럴 때 입력된(저장된) 순서를 알아야 오래된 캐시를 비울 수 있다. 이에 적용할 수 있는 자료구조 중 하나다. (현실적으로는 LRU기법으로 LinkedHashMap이라는 자료구조가 대부분을 차지하고 있어 많이 쓰이진 않으나 그나마 이해하기 쉬운 예시를 위해..)
TreeSet
TreeSet은 HashSet과 마찬가지로 입력 순서대로의 저장 순서를 보장하지 않으며 중복 데이터 또한 넣지 못한다. 다만 특별한 점이 있다면 SortedSet Interface의 이름을 보면 알 수 있듯 이를 구현한 TreeSet은 데이터의 ‘가중치에 따른 순서’대로 정렬되어 보장한다는 것이다. 앞서 PriorityQueue를 생각해보자. 데이터들이 입력한 순서대로가 아닌 값에 따라 정렬되어 Queue에 담아진다. 마찬가지로 TreeSet은 ‘중복되지 않으면서 특정 규칙에 의해 정렬된 형태의 집합을 쓰고 싶을 때 쓴다. 정렬된 형태로 있다보니 특정 구간의 집합요소들을 탐색할 때 매우 유용하다.
(Tree 라는 자료구조 자체가 데이터를 일정 순서에 의해 정렬하는 구조다. 거기에 더해진 것이 바로 Set인 중복값 방지 자료구조인 것이다.)
각 클래스별 생성 방법이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
/*
T는 객체 타입을 의미하며 기본적으로
Integer, String, Double, Long 같은 Wrapper Class부터
사용자 정의 객체까지 가능하다.
단, primitive type은 불가능하다.
*/
HashSet<T> hashset = new HashSet<>();
LinkedHashSet<T> linkedhashset = new LinkedHashSet<>();
TreeSet<T> treeset = new TreeSet<>();
SortedSet<T> treeset = new TreeSet<>();
Set<T> hashset = new HashSet<>();
Set<T> linkedhashset = new LinkedHashSet<>();
Set<T> treeset = new TreeSet<>();
적절한 자료구조 사용하기
자바에서 지원하는 대표적인 컬렉션 11가지를 알아보았다. 스크롤하기 귀찮을 수도 있을 것 같으니 다시 한 번 적어보자면 설명한 컬렉션은 다음과 같다.
•ArrayList
•LinkedList
•Vector
•Stack
•Queue(by LinkedList)
•PriorityQueue
•Deque(by LinkedList)
•ArrayDeque
•HashSet
•LinkedHashSet
•TreeSet
각각의 장단점은 앞서 설명했으니, 간략하게만 어떤 상황에 어떤 자료구조를 쓰는 것이 알맞은가에 대해 알아보자.
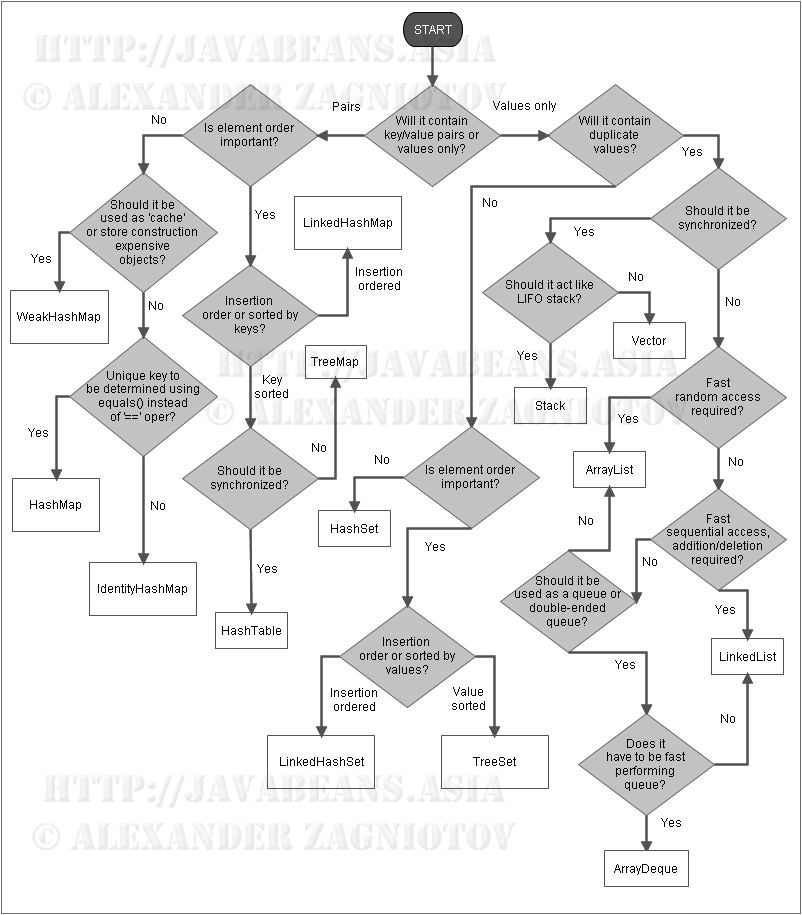
아직 Map에 대해서는 설명하지 않았다. 맨 처음 갈래에서 “Will it contain keyvalue pairs or values only?” 라고 묻는데, 자바에서는 Map을 컬렉션으로 보지 않기 때문에 이를 뺐지만, 간단하게 Map에 대해 말하자면 “키와 값이 쌍으로 이루어진 자료구조”를 의미한다. 하지만 설명한 Collection에 대한 것들은 모두 단일 value만 갖고 있기 때문에 첫 갈래에서 왼쪽으로 뻗어나가는 것들은 아직은 무시해도 된다.
마무리
지금까지 Collection Interface에 대해 알아보았다.
자료구조는 프로그래밍에 있어 거의 필수적인 요소라 할 수 있다. 물론 효율을 버리고 결과에만 집중한다면야 필요 없을 수 있겠지만, 그런 것이 아닌이상 알고리즘을 구현하기 위해 적절한 자료구조를 선택해야 할 것이다. C언어의 경우 표준 라이브러리에서는 이러한 자료구조를 지원하지 않는다. 그렇기 때문에 다른 사람이 만든 라이브러리(Glib 같은 라이브러리)를 찾아서 사용하거나, 직접 구현해야한다.
반면에 Java같은 경우 Collections Framwork로 위에서 설명한 자료구조 뿐만 아니라 매우 많은 자료구조를 지원하기 때문에 편리할 것이다. 다만, 앞으로도 쭉 개발자의 길로 혹은 프로그래밍 전문 분야로 나아갈 것이라면 자료구조에 대한 기본 이해와 구현은 필연적일 수밖에 없다.
그렇기 때문에 앞으로 자료구조를 직접 구현해보면서 공부해보자.